


New Paper Published on Generative AI and Strategic Decisions
Comparing the evaluations of AI evaluators with those of human experts in a new paper published in Strategic Management Journal co-authored with Jason Bell, Emil Mirzayev, and Bart Vanneste

My colleagues Jason Bell (Oxford), Emil Mirzayev (UCL), and Bart Vanneste (UCL), and I have published a paper called Generative artificial intelligence and evaluating strategic decisions in the Strategic Management Journal. There is quite a bit of discussion about the conditions in which generative AI bests human performance in areas such as creativity and other benchmarks. My co-authors and I were interested in a different kind of comparison: where there is no objectively correct answer, how does generative AI benchmark against humans?
One area where we often see these kinds of situations is in evaluations of strategies. Questions such as which product to invest in, which company to acquire, or which business model to pursue are all made amidst significant uncertainty about the future. So there is no objective way of making a “correct” decision today. In these situations, how do evaluations made by generative AI compare to those made by humans?
Two studies
We investigate this by looking at the evaluations of business models. We conducted two studies where we compare the evaluations made by generative AI against those made by human experts. We ask each AI and human evaluator to compare a pair of business models and evaluate which was more likely to succeed.
We run two studies. In the first, we generated 60 business models across 10 industries using GPT-4. Over fifty business school professors provided the human expert evaluations. In the second, we used business models that were submitted by entrepreneurs to a real-world competition that were evaluated by expert judges.
In both cases, we sent all pairs of business model comparisons to multiple LLMs, where we used two different prompting strategies and we asked the LLM to take on one of ten different roles (such as a journalist, a strategy professor, or an industry expert). So with the set of AI evaluations and human expert evaluations, we can see how the AI evaluations perform
The results
There are two main punchlines from our paper that I will highlight here: the first is about single evaluations and the second is about aggregating LLM evaluations.
Single evaluations
First, when we look at how well a single AI evaluation performs, we find that they are not very reliable. Specifically, we look at how consistent an LLM is when you ask it to evaluate business model A versus B, compared to B versus A (in other words, the same pair of business models, just flipping the order they are presented). Ideally, if the LLM selected B the first time, it would be consistent when the order is reversed. However, we find that the consistency of LLMs varies pretty dramatically, with the inconsistency driven by either a bias for the first option or the second option. In the graph below, the left side shows that consistency varies across LLM-prompts from below 30% to just above 80%.
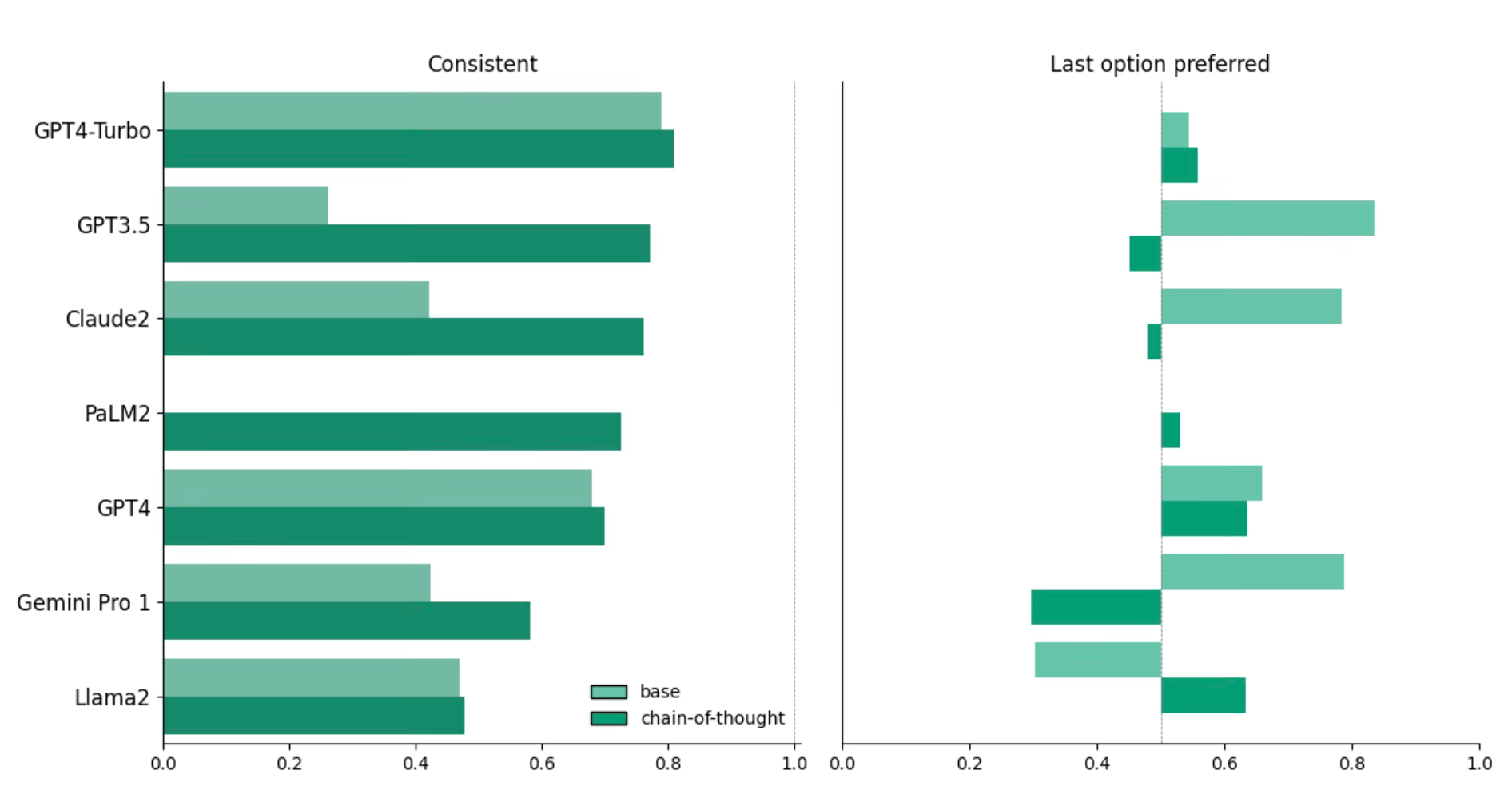
This result aligns with conversations I have had with managers—they often express skepticism about generative AI providing meaningful or valuable feedback on strategies or open-ended problems. Our results suggest that single interactions with LLMs (which is how most of us actually use the tool in practice) are not very reliable.
So it may seem that generative AI is not very useful for evaluating strategic decisions…
AI “Crowds”
… But! When we aggregate the individual evaluations (across LLMs, prompts, and roles), we start to see the potential in AI evaluations. We aggregate the pairwise evaluations in three ways: by keeping all evaluations made by a single LLM-role-prompt together (uniform); by mixing across LLM-role-prompts (mixed); and by throwing all evaluations together into one big evaluator (comprehensive).
What we find is that the different types of aggregations start to align more closely with the human experts (and agree with the experts more than human non-experts). The extent of agreement tends to increase as we move from the uniform to the mixed to the comprehensive AI evaluator across four different measures of agreement with the human experts.
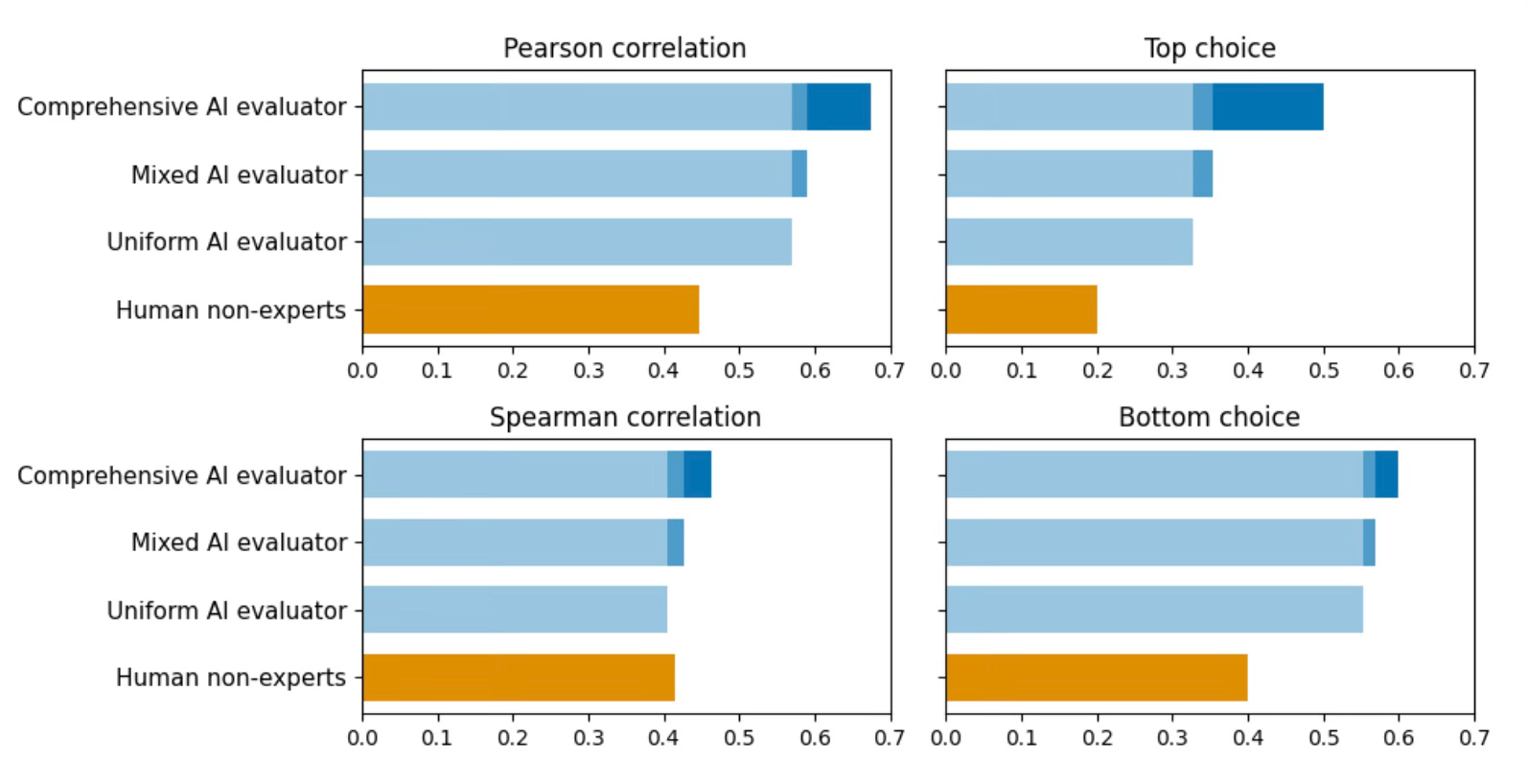
The takeaway
The tl;dr of our paper would be: while single evaluations made by generative AI are typically not consistent, creating generative AI crowds can yield evaluations that reflect those made by human experts.
Our research provides some important takeaways for firms implementing different generative AI systems within their organization and for startups looking to build new AI-based solutions. We show that generative AI can provide informational value on the evaluation of strategic decisions when aggregated across different models and prompting strategies. We think this notion of aggregation into “AI crowds” can provide helpful information and feedback in a number of managerial contexts where there is no objective or correct answer to be aiming at.
Historically, we have relied on one another—other humans—to get insight and feedback. Our work shows that AI might be an artificial source of feedback that can help us understand uncertain situations and make decisions.
Bonus
If you are more interested in seeing the paper presented, feel free to have a listen to a presentation I made at a Wharton conference on the paper.